The Microsoft Edge team recently tweeted about the reading mode, a feature that removes the clutter from webpages to read without distractions. It was not new to me, I learned about it when I was trying to understand how pseudo-protocols worked on Edge but I never played with it before, until that tweet reminded me its existence. If you are in a hurry watch the video PoC, otherwise, read below.
[ Update: this bug was patched on 2017-06-13 ]
To see the reading mode in action, load a website and click on the reading view button (the book icon).
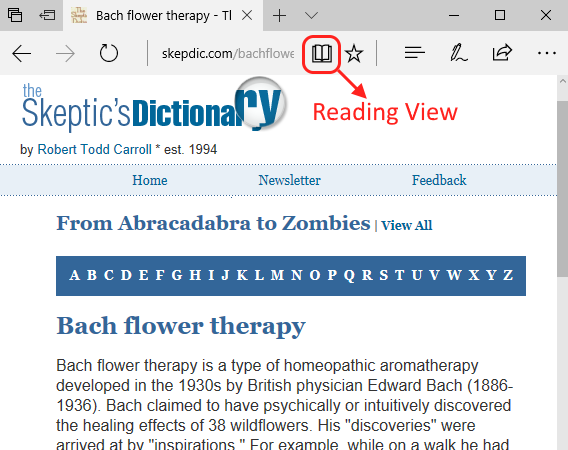
Which makes the webpage easier on our eyes.
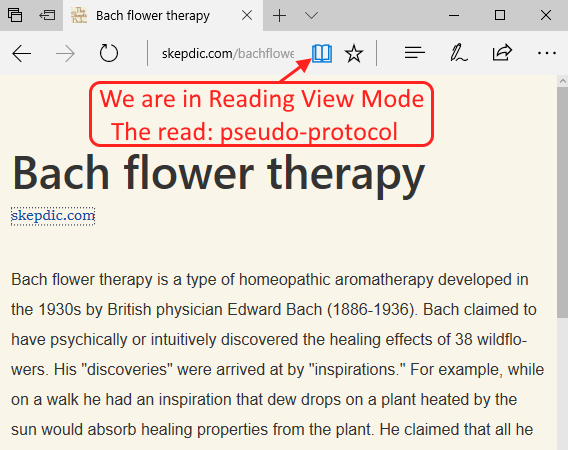
But what’s the real location of this decaf version of the webpage? Open developer tools (F12) and type location.href in the console. It becomes clear that Edge is adding the read: pseudo-protocol in front of the URL.
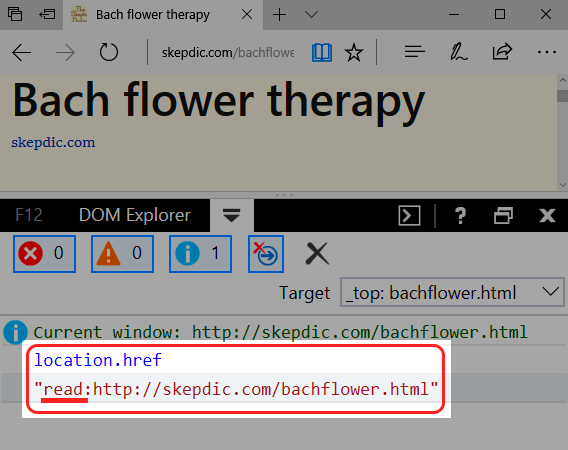
Reading-Mode is an internal resource
The reading-mode webpage has nothing to do with the one from the real website. If we take a look at the source (press CTRL U) we will see that there’s no trace of the original page, in reality, this is an internal resource hosted in the file-system:
C:\Windows\SystemApps\Microsoft.MicrosoftEdge_8wekyb3d8bbwe\Assets\ReadingView
Edge parses the content of the original webpage, removes iframes/scripts and other html tags, and finally renders it inside an iframe hosted in the internal reading view html. But all these tricks happen behind the scenes and the user ends up with the illusion of being in the original website because the address bar does not change, at all.
But, if Edge renders a webpage in reading mode by setting a “read:” protocol before the real URL, can we do that from a script? Can we load any URL in reading mode automatically?
Forcing any website into reading mode
Let’s see if we can force an arbitrary URL to render in reading-mode by prepending the read: protocol.
location.href = "read:http://www.cracking.com.ar"; // prepending read: does the trick
That worked perfectly well, but something called my attention: the URL in the address bar is cracking.com.ar but the rendered content comes from brokenbrowser.com. What? Well, if we go to cracking.com.ar we will see there’s a location.replace to brokenbrowser.com, but Edge did not update the address bar!
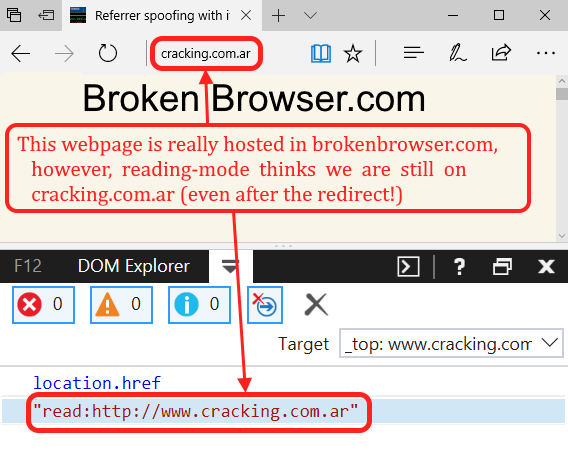
Finding an interesting redirect
This means that we can spoof any website with open redirects or even better, any website that is already redirecting to a website that we control. For example, if we can make google.com redirect to an evil page, then, the user will think the content is coming from google when in reality, it will be coming from evil.com.
By the way, it is not hard to spoof google considering that all its organic results are links that redirect to the target sites. For example, google has indexed a page “cracking-01.html” from cracking.com.ar, if we find the organic link that redirects to that page then we have the control. Makes sense? Let me open Chrome for a second and find a google redirect to cracking.com.ar. Remember: our goal is to find a google URL that redirects to a website that we control.
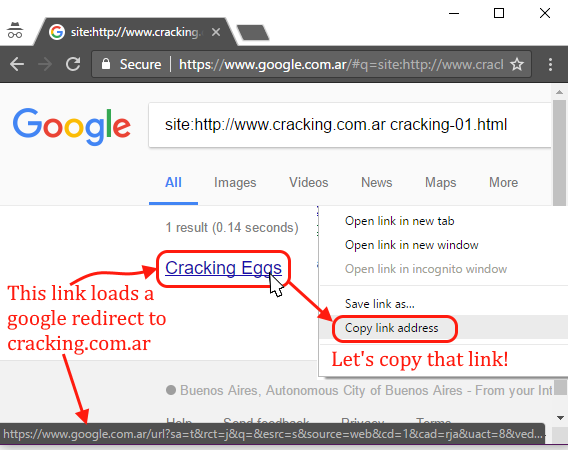
Redirecting in reading mode
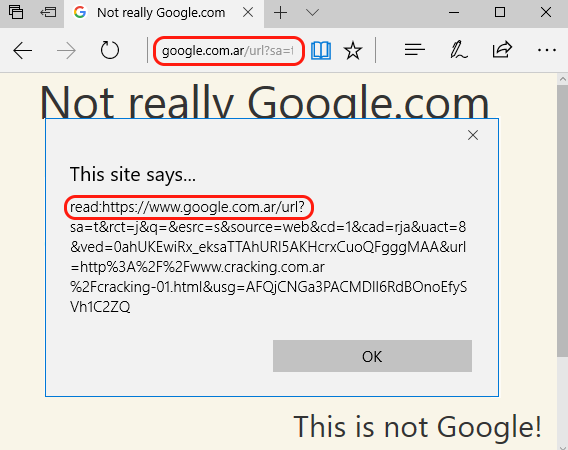
Now we have a google.com.ar URL that redirects to cracking.com.ar. The webpage in cracking.com.ar has a text saying “Not really Google” so we can easily identify where the content is really coming from. Below is the google redirect with the prepended read: protocol, opening that in Edge looks like this:
read:https://www.google.com.ar/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&cad=rja&uact=8&ved=0ahUKEwiRx_eksaTTAhURl5AKHcrxCuoQFgggMAA&url=http%3A%2F%2Fwww.cracking.com.ar%2Fcracking-01.html&usg=AFQjCNGa3PACMDlI6RdBOnoEfySVh1C2ZQ

Wow! We have a nice spoof, but damn it, we are in reading mode! This means that we don’t have full control of the look of our page. Remember: Edge is stripping a lot of html content before rendering our tricky page. For example, iframes and scripts are removed and javascript links don’t work (thanks to a META CSP tag rendered before our content). How can we customize this page and get rid of that yellowish background? How can we run scripts here?
Running scripts in reading mode
When we are in reading mode Edge does its best to keep our content static, meaning that no scripts are allowed to run, iframes are discarded, etc. In other words, our content ends up looking more like a book than a webpage. But we will try to break the barriers of this static reading mode where everything looks frozen.
Let me save your time, bug hunter: I manually tested a few html tags like iframe/script/meta but they were correctly removed. Then, I tried with an object/html tag and to my surprise, it worked!. This was easier than expected, object/html tags mimic iframes almost to the letter: they are html containers capable of running scripts.
So, if we add an object tag to our tricky page in cracking.com.ar and fire a prompt, it will look pretty convincing.
<!-- prompt.html does a window.prompt with the hard coded "google.com needs..." message --> <object data="http://www.cracking.com.ar/prompt.html"></object>

Right now, Edge thinks that the top page origin is google.com.ar (not true, it is cracking.com.ar) and the object/html origin is cracking.com.ar (this is true). The problem, bug hunter, is that we are trapped in this little box where we can throw prompts/alerts but we can not access the top.
Let’s say we want to change the background-color of the top page to white, or write a something to make the attack more convincing, we will need to bypass the same origin policy or set the top URL without changing the address bar. Let’s try the former and bypass the SOP.
Thinking outside the <object> box
How can we render a arbitrary html code on behalf of the top domain, so we can really access it? A data uri comes handy here. Instead of rendering content hosted in cracking.com.ar, we will render html from a data uri, just like this:
<!-- object rendering a data uri --> <object data="data:,<script>alert(top.location)</script>"></object> <!-- ACCESS DENIED data uris have their own unique origin -->
Oppss! Not so fast. Edge does not allow us to access any other document from this data uri, and that’s correct! All browsers render data uris as unique origins different from their creators, but on Edge this restriction is easy to bypass: a self-document.write after the page has been loaded is enough to set our location matching our parent.
<object data="data:,<script>
window.onload = function()
{ // Executing a document.write in a data uri after the onload
// changes the location of the object to its parent URL.
document.write('<script>alert(top.location.href)<\/script>');
document.close();
}
</script>"></object>
<!-- Now we have the same location as our top -->
Yes, bug hunter! We are really accessing google’s top domain now. At this point we have full access to the internal html code that renders the reading-mode magic, but instead of changing anything from it, let’s do a bold top.document.write and get rid of the yellowish background.
<object data="data:,<script>
window.onload = function()
{
document.write(
'<script>'+
'top.document.write(\'Trust me, we are on Google =)\');'+
'top.document.close()'+
'<\/script>');
document.close();
}
</script>"></object>

[ Test the PoC Live on Edge ]
[ Video in YouTube ]
If you want to have everything offline, grab the files from here.
Bug hunter, in my opinion nothing beats persistence, but in this case it was a lucky strike thanks to the original tweet and the initial redirect. I’m completely sure that more things can be found so please keep researching! My friendly reader, most of the times I don’t go deeply on these bugs, so there should be enough room to expand on them. Make them yours! Experience -like Richard Feynman- the pleasure of finding things out. I am not a scientist but still, this Amazon review deeply moves me:
Why do we do science? Beyond altruistic and self-aggrandizing motivations, many of our best scientists work long hours seeking the electric thrill that comes only from learning something that nobody knew before.
That’s it. Nothing can make you feel the “electric thrill” except your curiosity and persistence. Explore, try, research, learn and even more important: have fun!
Have a nice day! 🙂